The current state of AI image generation (early 2025)
Ever since the first diffusion model came around in 2015 they all have had some serious constraints on what was possible to achieve due to hardware limits. They still have issues, but progress is made in interesting ways.
You've probably already read about one of these big players:
Allt these have some impressive models, that can generate really nice 1-2 megapixel pictures for a fee. This can be fun for a while, until you try using them for something professional. You then realize that it will become tricky without addressing a list of issues.
Issues with AI images
- Relatively low output resolution (2048 x 2048 max, often 1024 x 1024)
- Incorrect anatomy (wrong number of fingers, missing teeth, weird skin texture)
- Bad at generating text (nonsensical glyphs)
- Faulty scale (subjects too large/small)
- Shadows not matching subject
- Imperfect patterns (sofas with uneven seats, organic; wavy lines in things that should be straight)
- Small generative artifacts (small, weird people in the background, random compression artifacts)
- Poor prompt adherence (two subjects show up when prompting for one)
- Copyright concerns about the underlying data used to train the model
 Human hand, placed on table (Stable Diffusion 3.5)
Human hand, placed on table (Stable Diffusion 3.5)

A luxurious corner sofa (Stable Diffusion 3.5)
Fixing it yourself
Alongside the proprietary models there are some worthwhile open-source alternatives worth mentioning, that you can run on your home computer (given that you have a graphics card with 8 GB VRAM and at least 16 GB RAM).
- Stable Diffusion 3.5, 1.0 in August 22, 2022
- SDXL July 18, 2023
- FLUX.1 August 1, 2024
Different checkpoints (a captured state of the model) are downloadable from Hugging face. They are all free for non-commercial use (some include commercial licenses).
All suffer from the same issues listed previously. The later models are better in many ways, FLUX can generate readable text in a limited way, it also has a better slightly understanding of human anatomy (but still not quite right as shown below with incorrect proportions and merged fingers).
 A Human hand, placed on table (Flux.1 dev)
A Human hand, placed on table (Flux.1 dev)

A luxurious corner sofa (Flux.1 dev)
A short note on NSFW
Some of these free checkpoints are trained on imagery that is NSFW (Not Safe For Work, meaning that they contain things like nudity, gore and monsters). This sometimes has to be mitigated by providing negative prompts or selectively excluding results, a thing to consider if building an automated public facing service.
The anatomy of a diffusion model
A diffusion model is stored in a safetensors file, there are others like ONNX or bin, but they usually contain the following.
- Image model (latent space)
- CLIP (Contrastive Language-Image Pretraining)
- VAE (Variational AutoEncoder)
A CLIP encoder encodes text to instructions on how a sampler should generate the image, also called the prompt. The VAE converts images to and from latent space (the internal format).
Using a backend
To escape having to write a large amount of Python code (some might actually be required though), to test these models, a backend software can be used. I personally use ComfyUI a graph based editor that enables combining or hot swapping different models into a workflow. Others of note are automatic1111 and InvokeAI.
Controlling image generation
Backends like ComfyUI offer granular control that standardized web interfaces can't accommodate by providing workflows. These workflows can do a lot more than the proprietary web services due to sheer flexibility.
Image to image
 A frowning person (Flux.1 dev)
A frowning person (Flux.1 dev)
A base image can be sent to the sampler along with the prompt, how much of the original image is used is determined by parameters.
Fixed seeds
Randomization can be controlled by using specific seeds to get the same output. In combination with varying other parameters to get subtle variations that can be selectively edited afterwards to exclude unwanted details (like hands with weird anatomy).
LoRA
If using text based prompts to generate a series of images, it is nearly impossible to get the subject to look alike between images due to randomization. A LoRA (Low Rank Adaptation) is like a patch for the model where a pre-trained custom subject can be inserted by using keywords in the prompt. LoRA construction is complex and requires a moderate to large amount of images of the subject.
ControlNet
A ControlNet is an external neural network that controls image generation via supplying additional conditioning on top of CLIP encoded text. It was concieved by 3 researchers (Lvmin Zhang, Anyi Rao, Maneesh Agrawala) in 2023. This can be used for specifying human poses or copying composition from another image or altering the style of an image.
Depth
A depth map can be used to control the subject/content of the image.
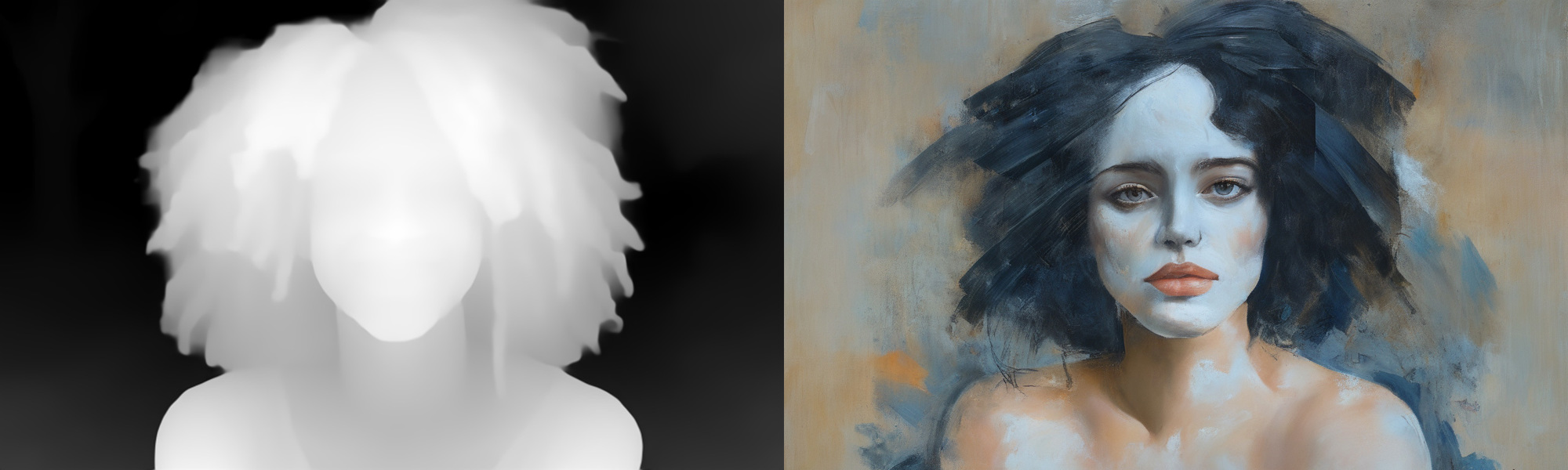 A painting of a woman (SDXL, Proteus v0.4 checkpoint)
A painting of a woman (SDXL, Proteus v0.4 checkpoint)
Canny/Scribble
A scribble or edge detected version of a source image can be used to control the image.
 A painting of a woman (Flux.1 dev)
A painting of a woman (Flux.1 dev)
Pose
A pose definition can be used to control the image.

A smiling person (SDXL, Proteus v0.4)
Inpainting/Outpainting
Parts of the image can be replaced partly or in full based on a mask, this can help remove/reduce unwanted details in the source image.

Example Inpainting from a ComfyUI tutorial.
IP Adapter
IP Adapter is a computer vision based way to supply a way to prompt using images, enabling style transfer.

Retro robot in forest (SDXL, base)
Upscaling
To fix the low resolution issues another AI model can be used to upscale the image through different methods, by either inferring some data or by just hallucinating more pixels based on the input image and a text prompt. One notable paid product that does this is Topaz Labs Gigapixel.
There are also plugins for ComfyUI that can split the image into tiles and stich them together to increase resolution. These upscalers work with the models latent space and use prompts to generate high quality results.

Close-up of image upscaled by 4x by Ultimate SD upscale
Summary
Given the above stated list of issues with generative AI and the amount of work that has to be put in to produce high quality imagery, the need for digital artists and engineers still exists and the difference in quality is the amount of work you put into generating/improving your images.
Kontakta oss

